【Python】Anacondaでパッケージが使えない
【問題】Anaconda上のSpyderでパッケージをインポートできない
ネットで拾った説明通り、ターミナルでパッケージを次のようにインストールする。ここではpandasパッケージを例に説明。
pip3 install pandas
Anaconda環境のSpyderで次のようにパッケージをインポートして使用しようとするとNot Found Moduleのエラーが発生
import pandas as pd
【原因】Anacondaの開発環境にパッケージがインストールされていない
ネット記事や教科書の多くでは、Pythonの開発環境(3系)にパッケージをインストールする想定であるため、pip3のコマンドを用いている。しかし、初学者にはややこしいことに、パッケージは自分が使用する開発環境にインストールしなければならない。Anacondaの開発環境をインストールしていると、すでにPythonの開発環境は2系、3系、Anacondaとなっているらしい。
【対処】Anacondaの開発環境に対してパッケージをインストールする
condaのコマンドを使ってpandasをインストールすればよい。なお、事前にcondaコマンドのパスを通しておく必要はあるので注意。
conda install pandas
これでパッケージが使えるようになった。試しにSpyderの画面上で再度importのコードを試したところ問題なく動作した。
import pandas as pd
以下のページが大変参考になりました。
www.sejuku.net
www.python.jp
【Python】Anacondaのpathを通す
【原因】Anacondaへのパスが通っていない
【対処】Anacondaのパスを通す
- Anacondaのインストールファイルのパスをコピー
Finderでanaconda3フォルダを開く。
Finder上で(shift+Command+G → ~/anaconda3)
binフォルダをoptionキーを押しながら右クリックして「binのパス名をコピー」をクリック。
- 使用シェルを確認する
echo $SHELL
bash か zsh かを確認
使用機では zsh だった。
- (シェルファイルがなければ)シェルファイルを作成する
シェルファイルが削除されていたので次項の操作ができなかった。
そのため、シェルファイルを作成した。
touch .zshrc
- シェルファイルを開く
シェルファイルがzshファイルなのでそれを開く。
open ~/.zshrc
なお、bashファイルの場合はこちら。
open ~/.bash_profile
- シェルファイルにパスを通す
テキストエディットで開いたシェルファイル末尾に以下の内容を入力する。
export PATH=***:$PATH
***にAnacondaのファイルパスを入れる。
最後にcondaコマンドが使えることを確認。
conda --version
以下の2つの内容をそのまま試しました。
timappleblog.com
ios-docs.dev
【R】クラスとデータ構造
Rで扱うデータの構造についてまとめます。
クラス(class)
クラス(class)の種類
Rで扱う値にはクラス(class)が存在します。クラスとは、データのタイプを意味しています。
データのクラスは class() で調べることができます。
これは裏パラメタのようなもので、コンソール画面では表示されません。
しかし、この違いを理解していないと、実際のデータ処理でエラーを連発することになります。
なぜなら、関数にインプットされる値には、関数ごとに特定のクラスが想定されているからです。
例えば、文字列である「こんにちは」の平均を求めることは不可能です。
実際に、平均値を求める mean() では、以下に記述する数値型(numeric)のデータが想定されています。
それでは、クラスの一覧とルールを説明します。
- 論理型(logical)
- 整数型(integer) *数値型(numeric)
- 小数点型(double) *数値型(numeric)
- 複素数型(complex)
- 文字型(character)
上から順に優先度が高く、下から順にデータの柔軟性が高い。
なお、整数型(integer)と小数点型(double)はRのクラス名表記では同じ数値型(numeric)として扱われる。
*優先度
クラスを指定しなかった場合に、上から順番に当てはまるかを確かめ、最初に当てはまったクラスが値に適用される。例えば「5.0」は整数型(integer)の「5」として扱われるが、「5.1」は小数点型(double)の「5.1」として扱われる。一方で、「"こんにちは"」などは文字列(character)として扱うしかない。
*柔軟性
クラスは下に行くほど当てはめられる値の範囲が広い。例えば、文字列(character)は「"こんにちは"」だけでなく、「5.0」を「"5.0"」の文字列として扱うこともできる。なお、文字型の特徴として、値は " " に囲まれている。
> a <- TRUE > class(a) [1] "logical" > b <- 5.0 > class(b) [1] "numeric" > c <- 5.1 > class(c) [1] "numeric" > d <- 1i > class(d) [1] "complex" > e <- "こんにちは" > class(e) [1] "character" > f <- "5.1" > class(f) [1] "character"
クラスの変換
クラスの変換は、as.クラス() の名前の関数によって行うことができます。
ただし、 "こんにちは" のような文字列を数値(numeric)にすることはできません。
> g <- 3.14 > class(g) [1] "numeric" > h <- as.character(g) > h [1] "3.14" > g <- 3.14 > #クラスがnumericであることを確認 > class(g) [1] "numeric" > #文字型に変換する。 > h <- as.character(g) > #文字型の証拠である""が確認できる。 > h [1] "3.14" > #もう一度、数値型に戻す。 > i <- as.numeric(h) > i [1] 3.14 > #文字列は数値型に変換できない。 > j <- "こんにちは" > as.numeric(j) [1] NA Warning message: NAs introduced by coercion
論理型(logical)である TRUE/FALSE は数値型としては、 1/0 として扱われます。
文字列として変換する場合にはそのまま "TRUE" "FALSE" として扱われます。
> k <- TRUE > l <- FALSE > as.numeric(k) [1] 1 > as.numeric(l) [1] 0 > as.character(k) [1] "TRUE" > as.character(l) [1] "FALSE"
因子型(factor)について
ここまで触れてきませんでしたが、 因子型(factor) というクラスが存在します。
これは、通常の代入において適用されるクラスではありません。
> g <- 3.14 > k <- TRUE > as.factor(g) [1] 3.14 Levels: 3.14 > as.factor(k) [1] TRUE Levels: TRUE
因子型(factor)は、主にデータ処理においてカテゴリカルなデータを扱う際に用いるクラスです。
入力値を文字列のように計算不可能なものとして扱います。
見た目の上では 文字型(character)と似ています。
ただし、因子型(factor)には水準(levels)というパラメタが存在します。
値を単に文字列として扱うのではなく、識別するためのパラメタです。
例えば、「そう思う」「少しそう思う」「どちらでもない」「あまりそう思わない」「そう思わない」という5件法のアンケートを行った結果、得られた順に、「そう思う」が2件、それ以外が1件ずつの回答が得られたとします(計6件)。
これをベクトルデータとして保存して、文字型(character)と因子型(factor)それぞれで扱った際の出力を確認します。
すると、因子型(factor)のみ水準のパラメタが含まれていることがわかります。
> x <- c("そう思う","そう思う","少しそう思う","どちらでもない","あまりそう思わない","そう思わない") > x [1] "そう思う" "そう思う" "少しそう思う" "どちらでもない" "あまりそう思わない" [6] "そう思わない" > as.character(x) [1] "そう思う" "そう思う" "少しそう思う" "どちらでもない" "あまりそう思わない" [6] "そう思わない" > as.factor(x) [1] そう思う そう思う 少しそう思う どちらでもない あまりそう思わない そう思わない Levels: あまりそう思わない そう思う そう思わない どちらでもない 少しそう思う
また、factor(x, levels, ordered) の関数とオプションによって、水準に順序を与えることができます。
これによって、順序性のある尺度の分析が行いやすくなります。
順序のパラメタがないと、例えば今後の記事で触れる latticeパッケージによるの histogram() で因子ごとの度数表を作成したい時などに、順序がバラバラになってしまって見栄えが悪くなります。
> x2 <- factor(x,levels=c("そう思わない","あまりそう思わない","どちらでもない","少しそう思う","そう思う"),ordered = TRUE) > x2 [1] そう思う そう思う 少しそう思う どちらでもない あまりそう思わない そう思わない Levels: そう思わない < あまりそう思わない < どちらでもない < 少しそう思う < そう思う
もちろん、与えるオブジェクトは直入力してもOKです。
> y <- factor(c("そう思う","そう思う","少しそう思う","どちらでもない","あまりそう思わない","そう思わない"), levels=c("そう思わない","あまりそう思わない","どちらでもない","少しそう思う","そう思う"), ordered = TRUE) > y [1] そう思う そう思う 少しそう思う どちらでもない あまりそう思わない そう思わない Levels: そう思わない < あまりそう思わない < どちらでもない < 少しそう思う < そう思う
データ構造
ここまで基本的に単一の値(value)を変数とすることを前提として説明しました。
しかし、ある値はデータとしてみた時の最小単位です。
ほとんどの場合、データは、1つ以上の値の集合からなります。
そして、Rでは、それらを x などの変数の中に代入して利用します。
この変数の中での値の結合の仕方ががデータ構造です。
ですから、変数の中にある値には、値自体のクラスと、属するデータ群(オブジェクト)としてのパラメタをもっています。
データ構造の種類
Rで扱われるオブジェクト(変数xとして想定されるデータ)には以下の種類とルールがあります。
- ベクトル(vector) :複合データの最小単位
ー1次元データを扱う。
ー構成される値のクラスが異なる場合、柔軟性の高いクラスに合わせて統一される。
- リスト(list):1つ以上のベクトルの合成
ー2つ以上のベクトルが結合される際に、それぞれの長さが異なってもよい。
ー最上段の列に変数名としての役割は想定されていない。
ーデフォルトでは列名は設定されない。
ー列の違いは属性の違いとしての意味をもたない。
ー列を縦結合したり、行を横結合したりする操作が可能。
ー平均を求めると全データの平均が求められる。
- データフレーム(data.frame):1つ以上のベクトル・リストを2次元に合成したもの
ー2つ以上のベクトル・リストが結合される際に、それぞれの長さは同じでなければならない。
ークラスは列ごとに異なってよい。
ー基本的に、行は個票、列は属性を表す。
―平均を求めると列ごとの平均が求められる。
- 配列(array):3次元を超える配列データ
- 度数表(table):list内の値の出現数をカウントしたデータ
ー単体ではなく、table(list)の形で用いる。
データ構造ごとの用途とR上での表記
値(value)
単なる任意の値です。データ構造ではなく、データの最小単位です。
例) 100
ベクトル(vector)
複数の値を並べたものです。一次元のデータです。イメージは以下の通り。
![]()
例)1 3 5 の3つの値をもつベクトル
その他のデータ構造は、分解するとベクトルになります。
逆に言うと、ベクトルを組み合わせ、その他のデータ構造を作成するために用いることができます。
なお、構成される値のクラスは統一されます。その際、当てはまる最も柔軟性の高いクラスが適用されます。
> x <- c(1, 3, 5) > x [1] 1 3 5 > y <- c(1, 3, 5, "こんにちは") > y [1] "1" "3" "5" "こんにちは"
xでは、いずれも数値型(numeric)ですから、 1 3 5 は数値として評価されます。
yでは、文字型(character)が混在したため、 "1" "3" "5" 即ち文字として評価されています。
リスト(list)
複数のベクトルを結合したものです。ベクトルの長さは異なっていても構いません。イメージは以下です。

例)「1 3 5」のベクトルと「2 4 6 8」のベクトルを結合したリスト
ベクトルはあくまで一次元のデータです。
「1 3 5」「2 4 6 8」両方の値を格納する際、「1 3 5 2 4 6 8」という1つのまとまりとしてしか扱えません。
> x <- c(1, 3, 5) > x [1] 1 3 5 > y <- c(2, 4, 6, 8) > y [1] 2 4 6 8 > z <- c(x, y) > z [1] 1 3 5 2 4 6 8
これに対して、リスト(list)はそれぞれを別個のベクトルとして扱うことができます。
そのため、種類の異なる複数のベクトルを変数に持たせたい際に便利です。
> w <- list(x, y) > w [[1]] [1] 1 3 5 [[2]] [1] 2 4 6 8
マトリックス(matrix)
値をマトリックス(行列)に配置したものです。配置しただけ、というのがポイントです。
例えば1~6までの値を2×3の行列に配置するとイメージはこうなります。
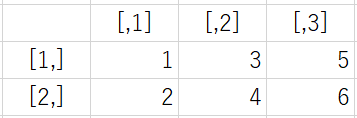
一見すると、後述するデータフレーム(data.frame)と似ているのですが、混同すると痛い目に合います。
マトリックス(matrix)は値を行列に配置しているだけなので、行や列に意味はありません。
ですから、デフォルトでは列名も存在しません。
値の集合でしかないので、行数と列数を変えて配置を組み直してもよいわけです。
同じく値の集合でしかないので、平均を求めると全ての値の平均を出力します。
このあたりは、データの作成と編集として別途まとめたいと思います。
ともかく、R上での表記を確認します。
> z <-matrix(1:6, nrow = 3, ncol = 2) > z [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6
データフレーム(data.frame)
1つ以上のベクトル・リストを行列に表したものです。
同じ行列でも、マトリックス(matrix)とは意味合いが変わります。
イメージとしては次のように、行は個票、列は属性を表します。
実務上も、R上もよく見られる形です。
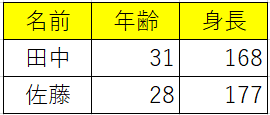
例えばアンケート結果を分析したいとき、上記の行列の意味は無視できないです。
勝手に行数と列数を変えて値を配置し直す、なんてことはあってはならないわけです。
平均を求める際にも、列ごとの平均に意味があるわけです。
そんなわけで、マトリックス(matrix)とは明確に異なる用途があることになります。
R上での表記は以下の通りです。
> x <- c("田中", "佐藤") > y <- c(31, 28) > z <- c(168, 177) > w <- data.frame( "名前" = x, "年齢" = y, "身長" = z) > w 名前 年齢 身長 1 田中 31 168 2 佐藤 28 177
見ての通り、列ごとに値のクラスが統一されていれば、列同士のクラスは異なっていても構いません。
配列(array)
少し特殊で、2次元データを並列でいくつも持つことができる結合の仕方です。
例えば次のように、2次元のマトリックスのデータがx,y,zと3つあるとします。


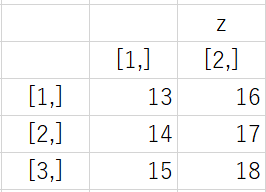
x : 1~6を2×3に配置 y : 7~12を2×3に配置 z:13~18を2×3に配置
これらのマトリックスを識別する3次元目の座標をもち、結合するのが配列(array)です。
さらにこれらの3次元データを識別する4時限目の座標をもたせれば、4次元データとなります。
例えば、複数の標本データを1つの変数の中に格納しておくことが可能です。
とりあえずは、上記の x,y ,z を結合した配列(array)のR上での表記を確認します。
> x <- matrix(1:6, nrow = 3, ncol =2) > y <- matrix(7:12, nrow = 3, ncol =2) > z <- matrix(13:18, nrow = 3, ncol =2) > w <- array(c(x,y,z), dim = c(3,2,3)) > w , , 1 [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 , , 2 [,1] [,2] [1,] 7 10 [2,] 8 11 [3,] 9 12 , , 3 [,1] [,2] [1,] 13 16 [2,] 14 17 [3,] 15 18
テーブル(table)
これも少し特殊な形で、単体で成立するのではなく、特定のデータの度数を集計して表現した形です。
アンケートの回答結果を集計したい時などに便利です。
例えば、次のようなアンケート結果があったとします。
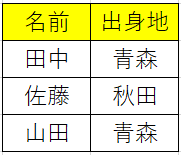
これをもとに出身地の度数を集計をしたらこうなります。

この操作を行うのが table() 関数であり、その結果の形式がテーブル(table)構造です。
R上では次のように表記されます。
> x <- data.frame("名前"=c("田中","佐藤","山田"), "出身地" = c("青森", "秋田", "青森")) > x 名前 出身地 1 田中 青森 2 佐藤 秋田 3 山田 青森 > y <- table(x$出身地) > y 秋田 青森 1 2
もちろん、クロス集計を行うこともできます。
このデータだと出力結果は不自然ですが、データの見え方はこのようになります。
> z <- table(x) > z 出身地 名前 秋田 青森 佐藤 1 0 山田 0 1 田中 0 1
今回扱っていませんが、tibbleというtidyverseパッケージで登場するdata.frameに類似したデータ構造もあります。
これはまた別途整理していきます。
以上、クラスとデータ構造について今の理解をまとめておきました。
正直、正確な理解という意味では次のようなリンクの方が厳密でしょう。
ベクトル、行列、データフレーム、リスト、配列、テーブルの違い
ただ、ここでは、自分の言葉でかみ砕いて記録しておくことができればよしとしたいと思います。
クラスとデータ構造の違いを理解しておかないと、データを作成したり、操作したりする段階で躓きます。
次回は、ここでの理解をもとに、実際にデータをR上で扱っていきます。
【R】ショートカットキー
R及びR Studioでは様々なショートカットキーがあります。
一覧を見たい時には、R Studioを立ち上げ、 Alt + Shift +K または Help > Keyboard Shortcuts Help によって参照できます。
この記事では、自分がお世話になる代表的なものだけをピックアップします。
OSはWindowsを想定しています。Macとは一部異なるものがあります*1。
ファイル
ファイルを開く
Ctrl + O
ファイルを保存
Ctrl + S
ファイルを閉じる
Ctrl + W
新規ファイル
Ctrl + Shift + N
作業フォルダの変更
Ctrl + Shift + H
カーソル移動
Sourceウィンドウにカーソルを移動
Ctrl + 1 *テンキーの数字では反応しない?
Consoleウィンドウにカーソルを移動
Ctrl + 2 *テンキーの数字では反応しない?
文字列の末尾へ
Shift + End
文字列の先頭へ
Shift + Home
カーソル固定してスクロール(上/下)
Shift + PgUp / PgDn
セクションジャンプ
Alt + Shift + J
タブ操作
タブの選択
Ctrl + Shift + .
タブの切り替え(右へ)
Ctrl + Tab
タブの切り替え(左へ)
Ctrl + Shift + Tab
コードの編集
カーソル行の実行
右上に実行ボタンがありますが、マウスを動かすのが面倒なのでこちらを多用します。
Ctrl + Enter
カーソル行までのコード全て実行
Ctrl + Alt + B
取り消す
Ctrl + Z
やり直す
Officeソフトとは異なるので、忘れがちですが重要です。Ctrl + Y ではない。
Ctrl + Shift + Z
代入の演算子 <- の挿入
Alt + =
pipe演算子 %>% を挿入(dplyrパッケージ)
Ctrl + Shift + M
カーソル行のコメント化(解除) *行頭に # を挿入
特に慣れないうちは、コメントをつけながらでないと自分が迷子になります。
Ctrl + Shift + C
セクションの作成
スクリプトが長くなる時はセクションが必須です。セクションジャンプと併用しましょう。
Ctrl + Shift + R
補完
R Studioのこの機能のお陰で、膨大な変数を処理したり、関数うろ覚えでコードを書いたりできます。
Tab
*PgUp PgDn で選択, Enter で決定, Esc で解除
その他
関数ヘルプの表示
?関数名 でも可能ですが、少し楽になります。
F1
検索・置換
スクリプトが長くなるほど強力なツールになりそうです。
Ctrl + F
対応する括弧の前まで移動
地味に役立ちますね。
Ctrl + P
*1:WindowsとMacのショートカットキーの違いについては、次のリンク先が詳しく掲載しています。http://kohske.github.io/R/rstudio/cheetsheet/RStudio-Rmdv2-cheat.pdf
【R】基本的な計算
Rでの基本的な計算をする方法をまとめていきます。
基本的な四則計算
足し算
足し算は + を使います。
> 1+2 [1] 3
引き算
引き算は - を使います。
> 2-1 [1] 1
かけ算
かけ算は * を使います。
> 2*3 [1] 6
割り算
割り算は / を使います。
> 3/2 [1] 1.5
その他の基本計算
累乗
累乗は ** または ^ を使います。2**3(2^3) は 2の3乗 になります。
> 2**3 [1] 8 > 2^3 [1] 8
余りのある割り算を行った際の整数の商
余りのある割り算を行った際の整数の商を求めるには %/% を使います。
> 10%/%3 [1] 3
余りのある割り算を行った際の余り(剰余)
余りのある割り算を行った際の剰余を求めるには %% を使います。
> 10%%3 [1] 1
特殊な計算
絶対値
絶対値を求めるには、 abs() を使います。
> abs(-10) [1] 10
対数 log
対数を求めるには、 log() を使います。
デフォルトでは底を eとした自然対数を求めます。
オプションで base = y を指摘することで、底の値を y にできます。
> log(1) [1] 0 > log(100) [1] 4.60517 > log(100,base = 10) [1] 2
底を2としたlog
底を2とするlog計算には log2() が使えます。通常のlog関数で底を2に指定するのと変わりません。
> log2(2) [1] 1 > log(2,base = 2) [1] 1
底を10としたlog
底を2とするlog計算には log10() が使えます。
> log10(10) [1] 1
四捨五入
小数点y桁でxを四捨五入する計算には、 round(x, y) が使えます。
yを負の数で指定することで、整数の四捨五入も可能です。
ただし、IEEE式の四捨五入であり、小学校で習うものとは微妙に違います。
詳細は以下のリンクが詳しいです。要約すると、五入とは限らず、五捨があり得ます。
JIS,ISO式四捨五入 - RjpWiki
> round(3.14, 1) [1] 3.1 > round(314, -1) [1] 310 > round(10.45, 1) [1] 10.4
小数点以下を切り捨て
小数点以下の切り捨てには、 floor() または trunc() が使えます。
round(x,y) でyを0桁に指定した際と
ただし、 floor() は小さい方に丸めるのに対して、trunc() は0に近づけて丸めます。
この違いが出るのは、負の値を処理する場合です。
> floor(3.14) [1] 3 > trunc(3.14) [1] 3 > floor(-0.5) [1] -1 > trunc(-0.5) [1] 0
小数点以下を切り上げ
小数点以下を切り上げる場合には、 ceiling() が使えます。
負の値を対象としている場合には、 trunc() と同じ計算結果になります(0に近づける切り捨てをするため)。
> ceiling(3.14) [1] 4 > ceiling(-0.5) [1] 0 > trunc(-0.5) [1] 0
小数点以下を四捨五入した切り上げor切り捨て
あくまで1桁の整数部分で四捨五入したい(切り捨てとは限らない)場合は、
roud(x,y) でyを0に指定する必要があります。
> round(3.14, 0) [1] 3 > round(3.54, 0) [1] 4
sin, cos, tan
それぞれ sin() cos() tan() を使うことで計算できます。
しかし、私は全くもってそれが何だったかを忘れてしまったので、当分使う機会はなさそうです。
高校数学を学び直さないといけません。
> sin(1.2) [1] 0.9320391 > cos(0.9) [1] 0.62161 > tan(1.2) [1] 2.572152
代数
実際に細々とここで述べてきたような計算をすることはそう多くはありません。
実際には、変数を代入して、代数計算を行います。
代入
変数の代入は、<- を使います(ショートカットキーは "Alt" + "=")。
以下のコードで x=10, y=3 となりました。
> x <- 10 > y <- 3
代数を用いた計算
これを使って計算できます。
> x + y [1] 13 > x - y [1] 7 > x * y [1] 30 > x ^ y [1] 1000 > x / y [1] 3.333333 > x %% y [1] 1
変数には一意の値だけではなく、データを代入することができます。
そして、それらのデータをまとめて扱い、計算する関数が存在します。
従って、繰り返し処理を行わずとも、膨大な計算を行うことができる点がRの強みになっています。
今回は基本的な計算のみ扱いました。今後はR本来の強みであるデータの処理について扱っていきます。
【R】インストール
Rを使うためには、Rをインストールする必要がある。
しかし、インストールの際には、OSごとに注意点が異なっている。
また、実務的には、R単独でも使用可能ではあるが、Rを使うための環境であるR Studioを同時に導入してしまった方が、その後の作業がスムーズでしょう。
自分自身、次のパソコンの環境がWindowsなのかMacなのかわかりません。
これらの点も考慮して、先人方が素晴らしいまとめをしてくださっているので、ここで新たに説明を行うより、それらを列挙しておく方が遥かによいと思いました。
そのようなわけで、この記事ではそれらのリンクを貼るだけにします。
*個人的な経験から、個人用PCでRをインストールする際には、ユーザー名が半角英数
字のみになっていないことによって生じるトラブルが非常に厄介。2番目のリンク先
の説明スライドが対処法も含めて詳しい。